Infrastructure automation
The Google Cloud Platform (GCP) can provide the IT infrastructure you need to run your own applications or services. In addition, the platform also provides many products and services that can be used to build your complete IT landscape. Setting up infrastructure no longer includes provisioning hardware, patching operating systems and cable wiring up network components.
Instead, you now manage resources such as virtual machines, accounts, datastore, networks, enable APIs and setting permissions.
Basically, given a GCP project, you can have full control of managing such resources using either the Console, the gcloud tool or even program against their published API using a Google supported library.
There is a need for automating this process of setting up IT infrastructure. By describing the infrastructre (e.g. as code)
- you can test it and apply to different execution environments (test,staging, production)
- you are forced to think about the order in which resources are created and what permissions you actually need to add
- team members can read how infrastructure is composed and you will have a single location (e.g. a git repo) where this can be stored with proper version control.
Infrastructure state
Two approaches for describing infrastructure are:
- describe the state in which you want infrastructure to be
- describe the steps to reach that state
For the first method, several tools exists such as Terraform and Google’s own Deployment Manager.
Using one or more descriptor files (YAML, JSON, HCL, properties) you can specify what resources you need and with what properties.
Automation of the second method can be done by writing (shell, make) scripts that use command line tools such as gcloud, gsutil and kubectl.
Tooling supporting the first method add an abstraction layer to the actual API calls.
Such tools require additional documentation to read and understand.
Troubleshooting problems with the descriptor can sometimes be hard to solve because it hides complexity which increases the perception of magic.
Tooling supporting scripts are typically bash and make. Such tools only require basic Unix skills and the actual command (gcloud) is very well documented and, even more important, kept up to date with the latest APIs. Problems with the execution of a command are simply reported and provide details about why this step failed. However, the development and execution of these scripts can be improved by add explicit organisation.
Infrastructure by migrations
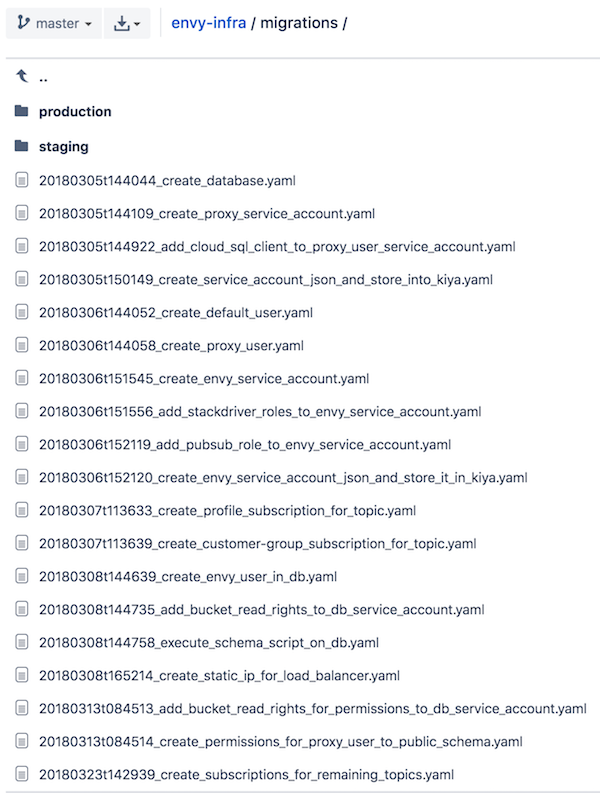
A migration is a change to infrastructure described by one of more shell commands that add, change or remove resources. Each migration is stored in a separate file and should result in a small change (add a service account, set IAM permission, enable API). The order of processing migration files is important and therefore each file has a name that is prefixed with a timestamp.
20180214t071402_add_myservice_service_account.yaml
The name of the file should summarise what its effect on infrastructure is.
Migration files use the YAML format that is structured, easy to write and can have comments.
This example has the following definition and uses the gcloud command:
# add envy service account
do:
- gcloud iam service-accounts create envy --display-name "Envy Service"
undo:
- gcloud iam service-accounts delete envy
Running this migration will create a new service account by simply executing the first command line of the do section.
You can rollback this change by executing the undo section which must have a command that reverses the effect.
Because migrations are ordered by timestamp, the state is reached by running each migration in order. The state of infrastructure for a given GCP project is known by the filename of the last applied migration. To make running the migrations idempotent, all migrations before the last applied one can be skipped. Therefore, it is important to store the (filename of the) last migration such that if new migrations are added, only those need to be runned.
gmig, a tool to work with migrations
The gmig tool is a lightweight, open-source, tool that creates and runs migrations. It requires a small configuration file to specify the GPC project, region, zone and bucket. A Google Storage Bucket is used to remember the last applied migration ; the current state.
gmig init my-project
Initializes a new migration project, by creating the my-project folder and placing a template configuration in my-project/gmig.json.
You must still name the bucket that needs to used.
{
"project": "my-project",
"bucket":"mycompany-gmig-states",
"state":"gmig-last-migration"
}
gmig new “add a new service account”
This will create a new migration from a basic template and timestamp it.
The template includes a do and an undo section.
For an example, see earlier in this article.
gmig up
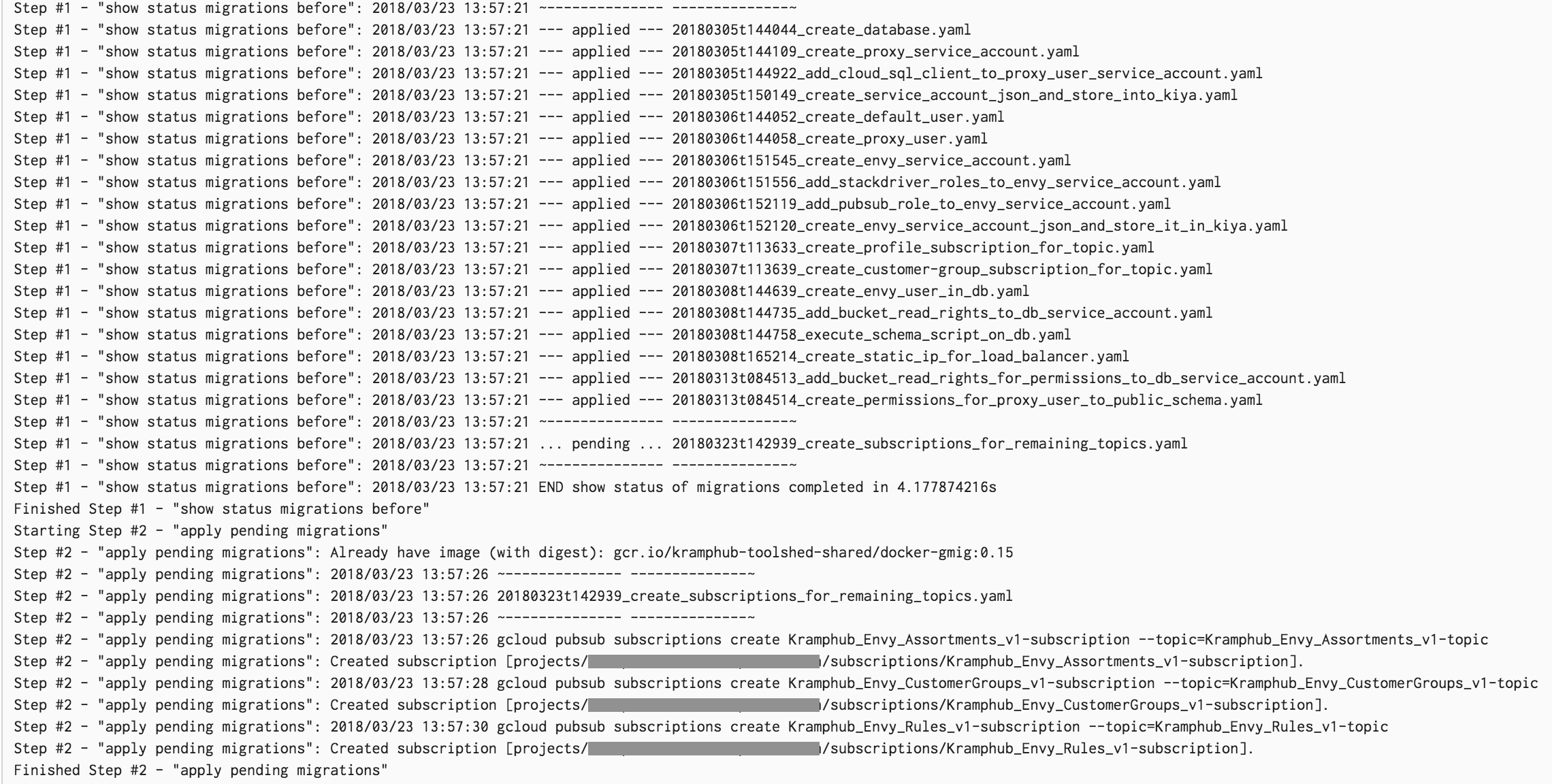
This command will run all pending migrations compared to the last applied one.
Running a migration means executing all the commands of all the do sections.
For each completed successful migration, the infrastructure state is updated in your specified Bucket.
The snapshot below is from running gmig up staging after creating a new migration for additional Pub/Sub topic subscription.
Before running the migrations, gmig status staging shows the current state which shows that the last migration is pending.
If you are interested in using this tool then visit http://github.com/emicklei/gmig.
Why not Terraform?
The terraform tool lets you describe the desired state of your infrastructure and will store the final state in e.g a version controlled repository.
When applying this description, the tool finds the differences between the existing and the desired state.
Based on these differences, the terraform tool will make the required changes to the infrastructure.
The terraform tool was considered for our startup to implement our (continuous) automated deployment process, but we decided against it because:
- At that moment, we had teams of developers who are not familiar with this tool and its DSL language ; it meant learning a new tool and the google provider.
- Before starting the automation, developers collected all required
gcloudandkubectlcommands for manual deployment ; we knew what was needed. - Some of our developers were used to working with migrations for database deployments (see MyBatis migrations) ; the pro’s and con’s are known
- Although not verified, we felt that using a DSL for this task could raise the level of magic but also may prevent us from doing customizations (shell scripts).
- We believe understanding the actual Cloud APIs (options etc) is really needed to create the resources; why not use the Google provided tools.
For the reasons mentioned, we decided to invest in this small helper tool to organise our collected commands such that we could have reproducible infrastructure.